See it in action
Everything runs on your machine.
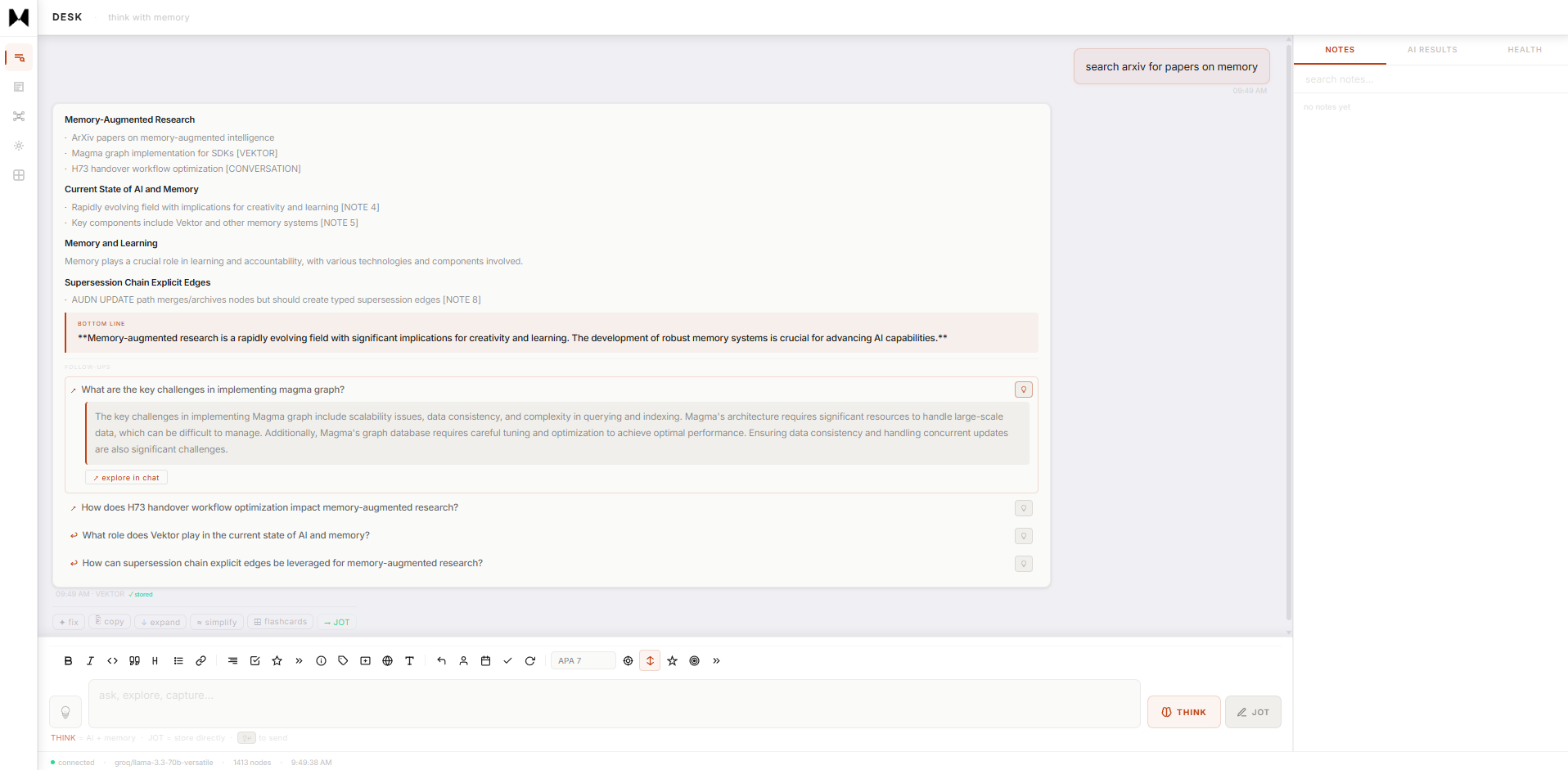
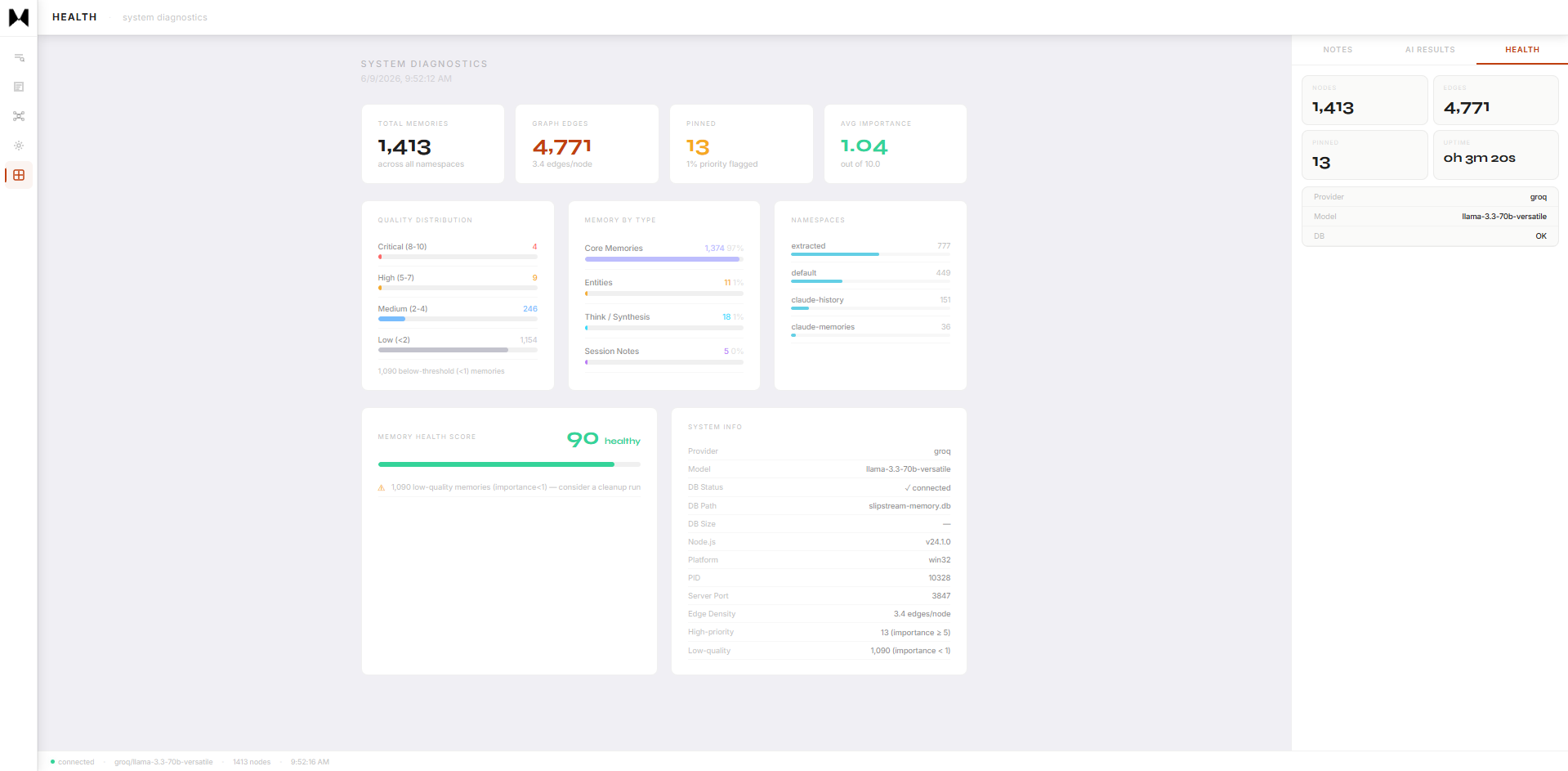
GRAPHD3 force graph · 4,200+ memories · semantic · causal · temporal · entity layers
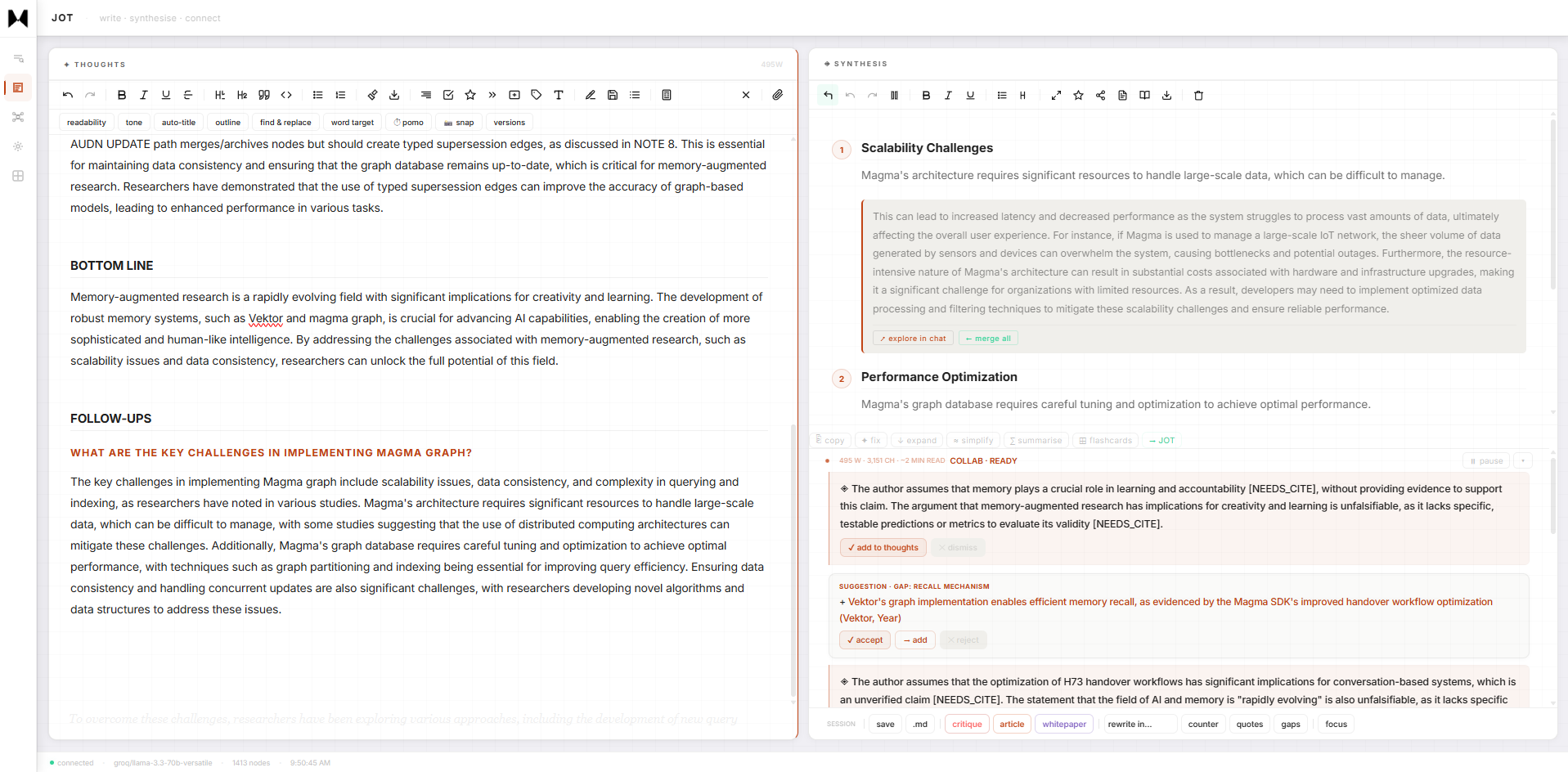
GRAPHAll-edge view · 22,496 temporal edges · orphan filter · namespace selector
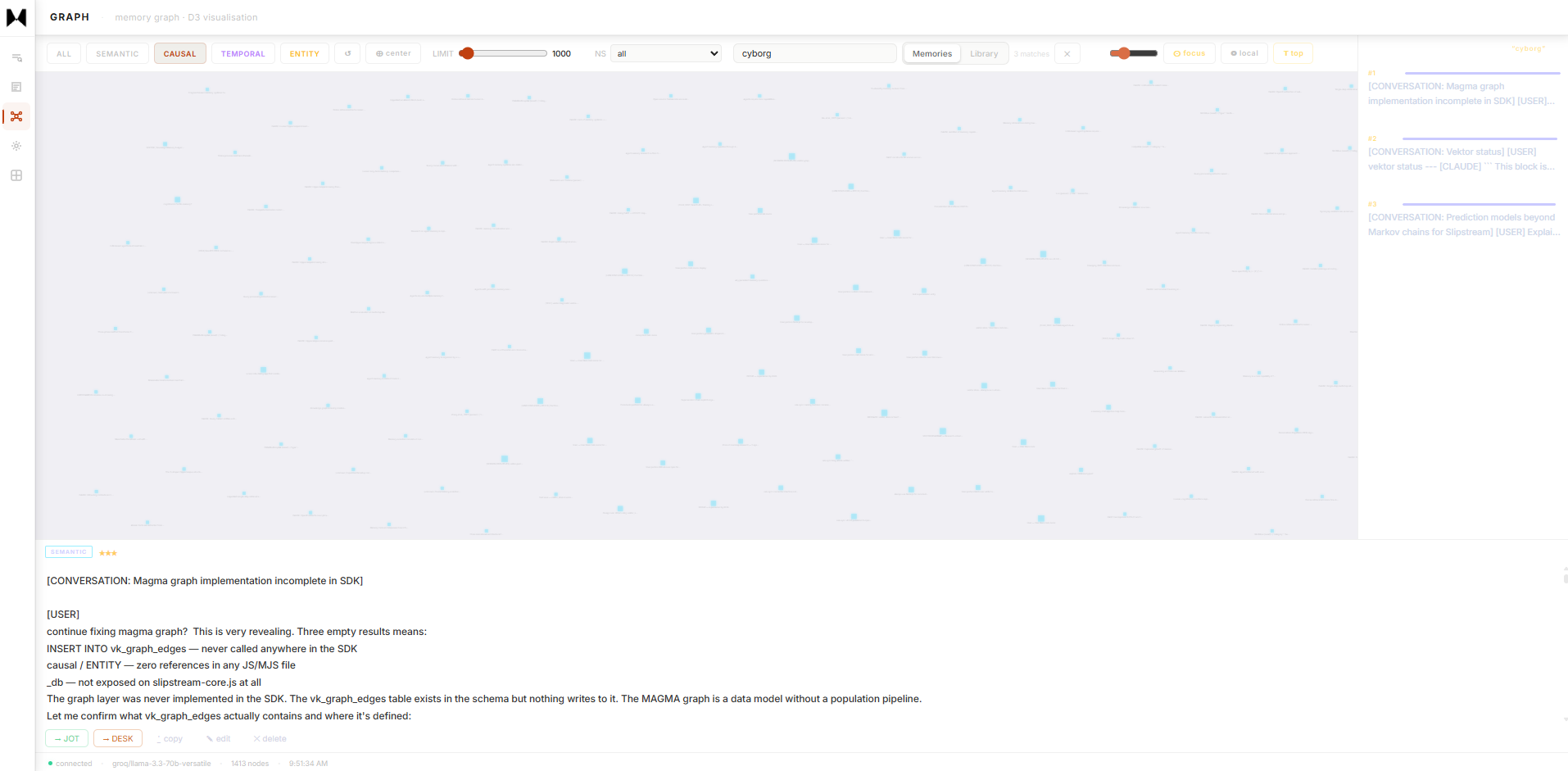
SEMANTICSemantic layer · vector similarity edges · concept clustering
CAUSALCausal layer · cause → effect chains · decision trail preserved
TEMPORALTemporal layer · chronological memory flow · time-ordered recall